

Making data pipelines with the History server
As new Insider's Guide classes are no longer being offered, this site is not currently being updated. Please refer to NCBI's E-utilities documentation for more up-to-date information.
One of the advantages of using EDirect to work with E-utilities in a Unix environment is Unix’s built in ability to combine commands together, taking the output of a command and using it as the input for a different command. As we previously mentioned, Unix accomplishes this using the “|” character, which allows you to “pipe” the output of one command into another command to be used as input.
EDirect commands can be combined together in this way, using “|”. For example:
esearch -db pubmed -query "seasonal affective disorder" | efetch -format xml
At first glance, this line of code is simple. We execute an esearch command to search a database (PubMed) for a query (“seasonal affective disorder”). The results of the query (a list of PMIDs that match the search criteria) are then piped into the efetch command, which retrieves full XML records for each PMID.
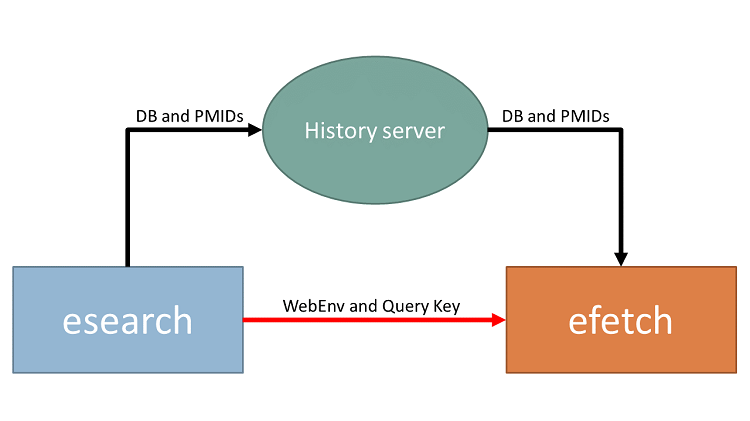
In reality, however, things are a little more complicated. The PMIDs from the esearch are not being piped directly into the efetch. Both esearch and efetch, as well as several other EDirect commands, make use of the E-utilities History server.
This History server keeps track of your previous queries, just like the History function in the PubMed Advanced Search Builder. Rather than outputting a list of PMIDs, esearch saves that list of PMIDs on the History server, and outputs two pieces of information which let you retrieve that list later: a Web Environment string (which identifies your specific history, as opposed to another user’s history), and a Query Key (identifying which specific set of results you would like to retrieve).
When you pipe the output of an esearch to an efetch, you are actually piping the Web Environment string and Query Key from the esearch to the efetch. The efetch then uses that information to retrieve the correct list of PMIDs from this History server, and uses that list of PMIDs as input.
In most cases, you can ignore the History server, and think of “|” as sending PMIDs from one command to the next. However, the History server makes it possible to create some longer and more powerful data pipelines, so it is important to understand what is at work.